Preface
本文为阅读 “Spark SQL内核剖析” 第三章 “Spark SQL 执行全过程概述”所做的归纳和整理。以下内容主要基于Spark 2.1 & Spark 2.2。首先,作者在该章的第一部分介绍了Spark SQL 执行优化器Catalyst涉及的重要概念,包括InternalRow, TreeNode体系和Expression体系。在该章的第二部分,作者介绍了从一段SQL语句到Spark可以执行的RDD[InternalRow]类型的转换所要经历的三个阶段, 逻辑计划, 物理计划以及代码的生产以及提交。
Catalyst涉及的重要概念
本节先简要介绍C a t al y st 中涉及的重要概念和数据结构,主要包括I n t e r n a l R o w体系、T r e e N o d e体系和E x p r e s si o n 体系
InternalRow
I n t e r n a l R o w 就是用来表示一行行数据的类,因此图3. 3 中物理算子树节点产生和转换的R D D类型即为R D D[ I n t e r n a l R o w] 。
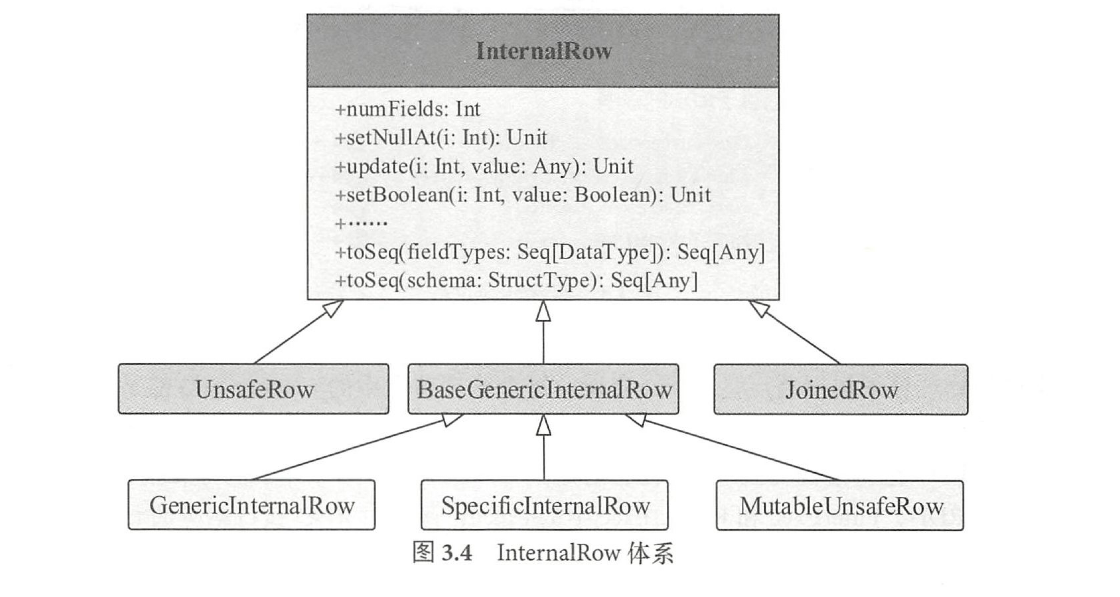
InternalRow体系
B a s e G e n e r i c l n t e r n a l R o w :
同样是一个抽象类,实现了I n t e r n a l R o w 中定义的所有g e t 类型方法,这些方法的实现都通过调用类中定义的g e n e r i c G e t 虚函数进行,该函数的实现在下一级子类中
1.G e n e r i c l n t e r n a l R o w

GenericInternalRow
不可变 ,G e n e r i c l n t e r n a l R o w 构造参数是A r r a y [ A n y ]类型,采用对象数组进行底层存储,g e n e r i c G e t 也是直接根据下标访问的。 这里需要注意,数组是非拷贝的,因此一旦创建,就不允许通过s e t 操作进行改变。
2.S p e c i f i c i n t e r n a l R o w
可变 ,S p e c i f i c l r 出r n a l R o w 则是以A r r a y [ M u t a b l e V a l u e ] 为构造参数的, 允许通过s e t 操作进行修改
3.M u t a b l e U n s a f e R o w
Joined Row
顾名思义,该类主要用于J o i n 操作,将两个I n t e r n a l R o w 放在一起形成新的I n t e r n a l R o w。使用时需要注意构造参数的顺序。
Unsafe Row
不采用J a v a 对象存储的方式,避免了J V M中垃圾回收(G C)的代价。此外,U n s a f e R o w 对行数据进行了特定的编码,使得存储更加高效。
Tree Node体系
T r e e N o d e 类是S p a r k S Q L中所有树结构的基类,定义了一系列通用的集合操作和树遍历操作接口。
T r e e N o d e 内部包含一个S e q [ B a s e T y p e ] 类型的变量c h i l d r e n 来表示孩子节点。
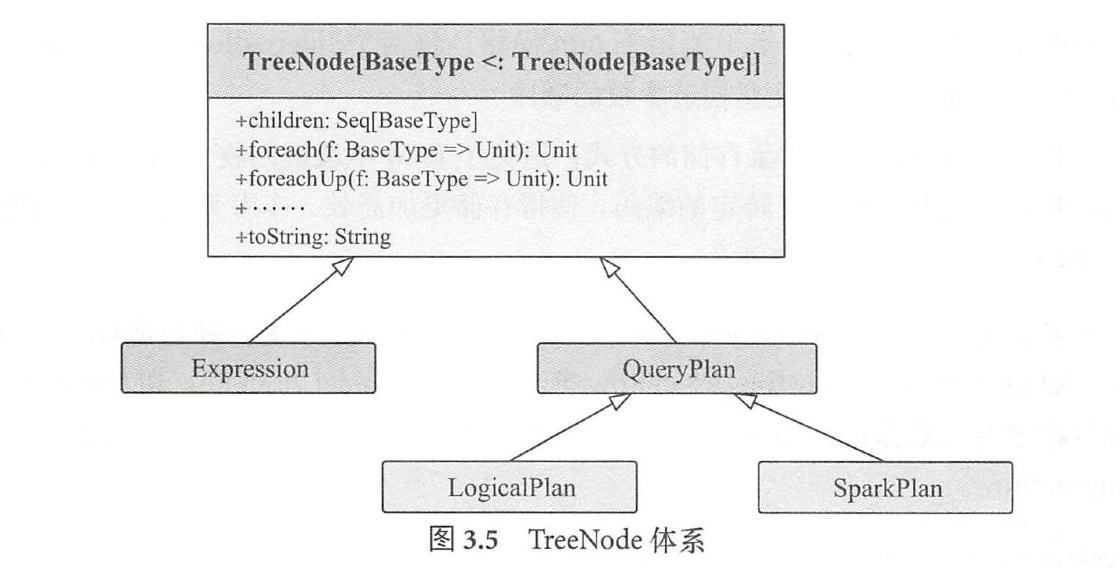
TreeNode体系
两个子类继承体系
T r e e N o d e 提供的仅仅是一种泛型,实际上包含了两个子类继承体系,
- Q u e r y Plan
- E x p r e s s i o n 体系
基本操作
TreeNode basic operation
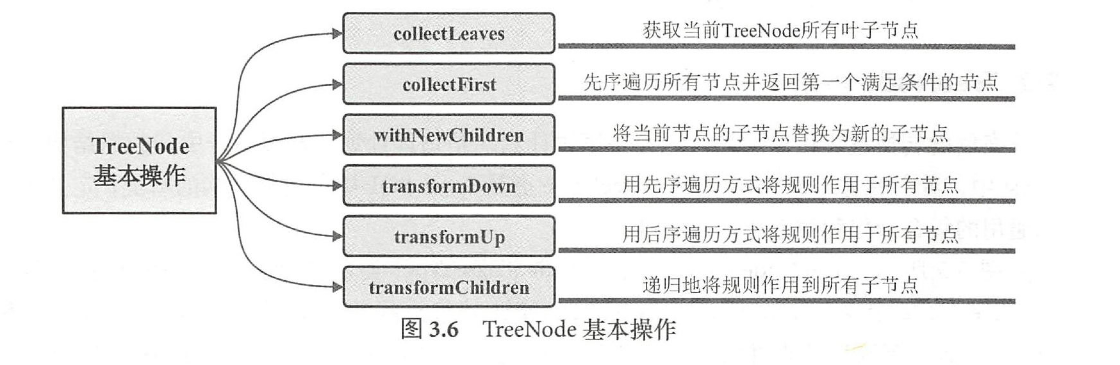
TreeNode基本操作
- C a t a l y s t 中还提供了节点位置功能,即能够根据T r e e N o d e 定位到对应的S Q L 字符串中的行数和起始位置。
Expression
表达式一般指的是不需要触发执行引擎而能够直接进行计算的单元,例如加减乘除四则运算、逻辑操作、转换操作、过滤操作等。
- 在E x p r e s s i o n 类中,主要定义了5 个方面的操作
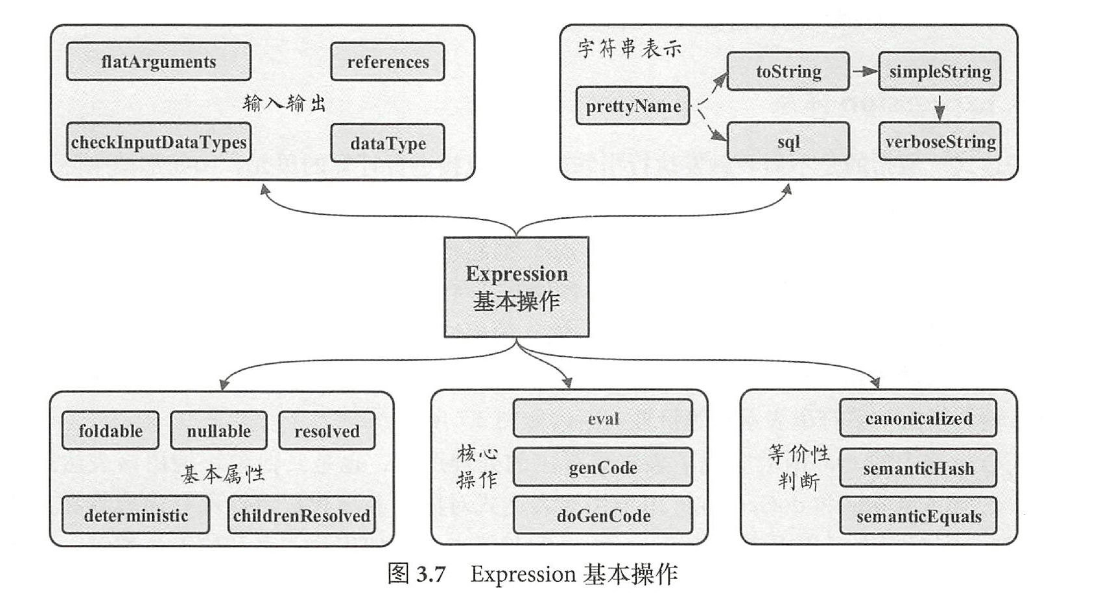
Expression基本操作
基本属性
Foldable
该属性用来标记表达式能否在查询执行之前直接静态计算。目前,f o l d a b l e 为t r u e 的情况有两种
- Literal
第一种是该表达式为L i t e r a l 类型(“字面值”,例如常量等) - Child Expression Foldable
第二种是当且仅当其子表达式中f o l d a b l e 都为t r u e 时
Deterministic
- 协助算子优化(谓词下推)
该属性用来标记表达式是否为确定性的,即每次执行e v a l 函数的输出是否都相同。考虑到S p a r k 分布式执行环境中数据的S h u f f l e 操作带来的不确定性,以及某些表达式(如R a n d 等)本身具有不确定性,该属性对于算子树优化中判断谓词能否下推等很有必要。
r e f e r e n c e s
canonicalized
规范化处理会在确保输出结果相同的前提下通过一些规则对表达式进行重写
SemanticEqual
判断两个表达式在语义上是否等价。
- 两个表达式都是确定性的( d e t e r m i n i s t i c 为t r u e )
- 两个表达式经过规范化处理后(C a n o n i c a l i z e d )仍然相同。
核心操作
输入输出
字符串表达式
等价性判断
从SQL 到 RDD
一个简单的例子
1 | val spark = SparkSession.builder().appName("example").master("local").getOrCreate() |
上述代码主要做了如下几件事情
(1)创建SparkSession, spark程序的入口
(2)读取数据(数据源可以为本地文件, hdfs 或者 hive等)
(3)执行spark sql语句并将结果收集到driver端
Logic Plan
逻辑计划阶段会将用户所写的S Q L 语句转换成树型数据结构(逻辑算子树),S Q L 语句中蕴含的逻辑映射到逻辑算子树的不同节点
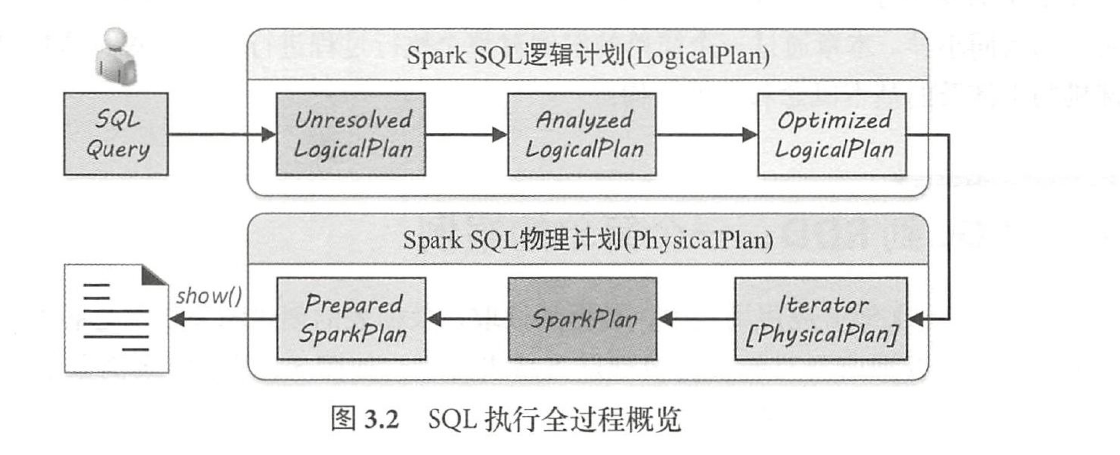
SQL执行全过程概览
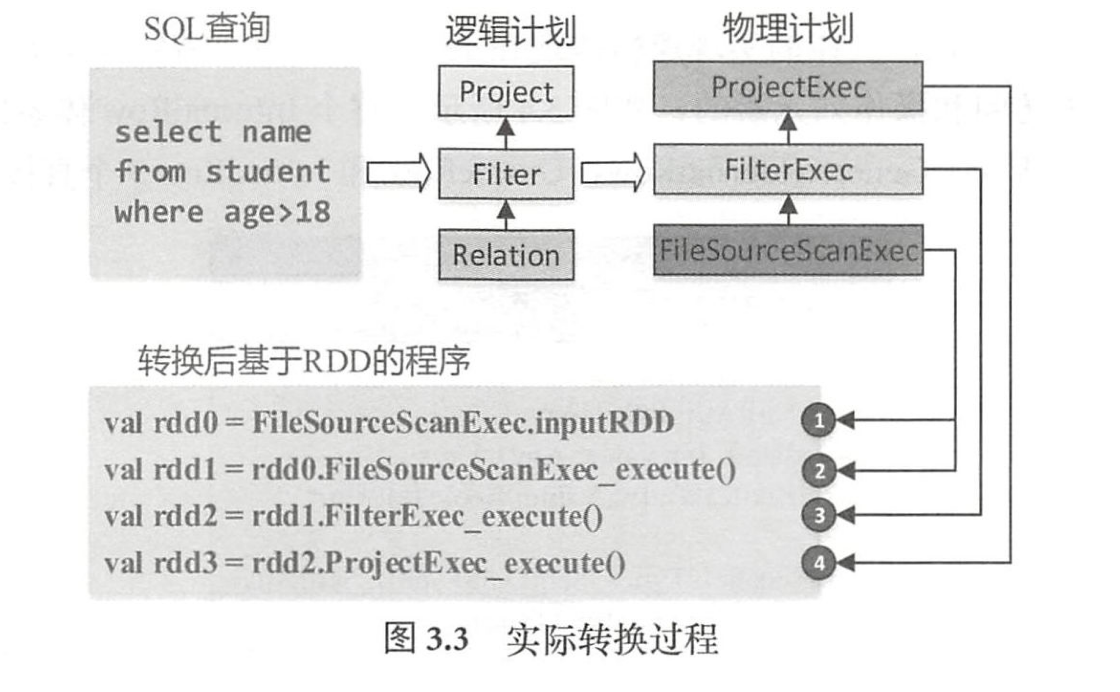
实际转换过程
逻辑算子树的生成过程经历3 个子阶段
- Unresolved Logic Plan
U n r e s o l v e d L o g i c a ! P l a n - Analyzed Logic Plan
A n a l y z e d L o g i c a l P l a n - Optimized Logic Plan
O p t i m i z e dlo g i c a l P l a n
Physical Plan
物理计划阶段将上一步逻辑计划阶段生成的逻辑算子树进行进一步转换,生成物理算子树。物理算子树的节点会直接生成R D D或对R D D进行t r a n s f o r m a t i o n 操作(注:每个物理计划节点中都实现了对R D D进行转换的e x e c u t e 方法)
- Interator[physical plan]
生成物理算子树的列表I t e r a t o r [ P h y s i c a l P l a n ] - Spark Plan
从列表中按照一定的策略选取最优的物理算子树(S p a r k P l a n ) - Prepared Spark Plan
对选取的物理算子树进行提交前的准备工作,例如,确保分区操作正确、物理算子树节点重用、执行代码生成等,得到“准备后”的物理算子树(P r e p a r e dS p a r k P l a n)
Submit
物理算子树生成的RDD执行a c t i o n 操作
- Driver端运行
从S Q L 语句的解析一直到提交之前,上述整个转换过程都在S p a r k 集群的D r i v e r 端进行,不涉及分布式环境。 - Physical Plan 根结点 ProjectExec
生成的物理算子树根节点是P r o j e c t E x e c ,每个物理节点中的e x e c u t e 函数都是执行调用接口,由根节点开始递归调用,从叶子节点开始执行。 - F i l e S o u r c e S c a n E x e c 叶子执行节点中需要构造数据源对应的R D D , Filter E x e c 和P r o j e c t E x e c 中的e x e c u t e 函数对R D D 执行相应的t r a n s f o r m a t i o n 操作。
- Spark S Q L内部实现上述流程中平台无关部分的基础框架称为C a t a l y s t
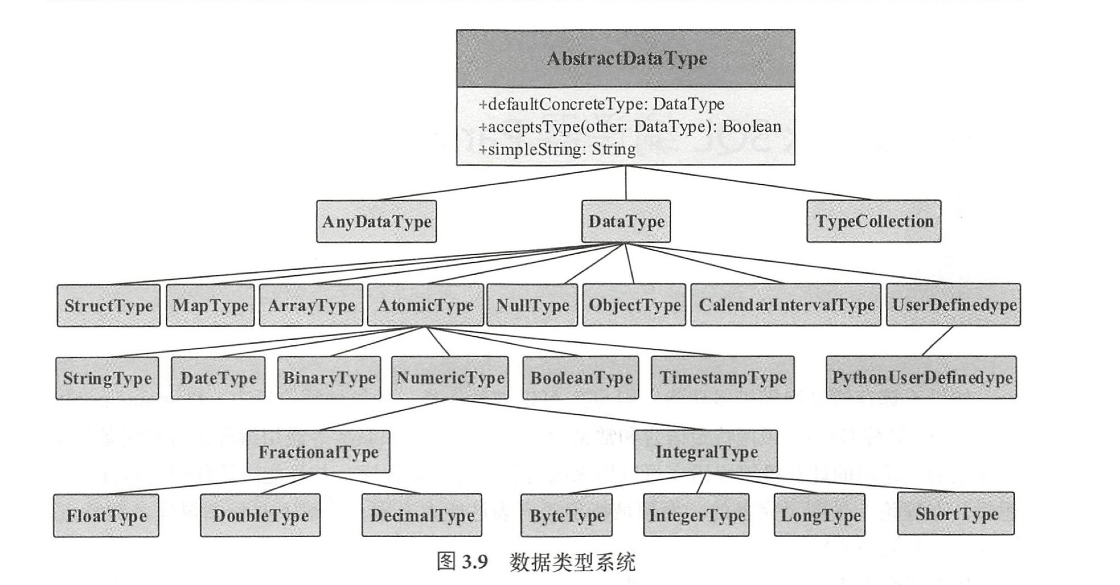
内部数据类型
数据类型主要用来表示数据表中存储的列信息,常见的数据类型包括简单的整数、浮点数、字符串,以及复杂的嵌套结构等。