Kafka基础
基本介绍
“官网”
Technically speaking, event streaming is the practice of capturing data in real-time from event sources like databases, sensors, mobile devices, cloud services, and software applications in the form of streams of events; storing these event streams durably for later retrieval; manipulating, processing, and reacting to the event streams in real-time as well as retrospectively; and routing the event streams to different destination technologies as needed.
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
工作原理
分布式系统
根据TCP协议通信
Servers
Kafka is run as a cluster of one or more servers that can span multiple datacenters or cloud regions. Some of these servers form the storage layer, called the brokers. Other servers run Kafka Connect
to continuously import and export data as event streams to integrate Kafka with your existing systems such as relational databases as well as other Kafka clusters.
Clients
They allow you to write distributed applications and microservices that read, write, and process streams of events in parallel, at scale, and in a fault-tolerant manner even in the case of network problems or machine failures.
核心概念
In Kafka, producers and consumers are fully decoupled and agnostic of each other, which is a key design element to achieve the high scalability that Kafka is known for.
- Event(事件)
- Producers(生产者)
- Consumers(消费者)
Event
Events are organized and durably stored in topics. Very simplified, a topic is similar to a folder in a filesystem, and the events are the files in that folder. An example topic name could be “payments”. Topics in Kafka are always multi-producer and multi-subscriber: a topic can have zero, one, or many producers that write events to it, as well as zero, one, or many consumers that subscribe to these events. Events in a topic can be read as often as needed—unlike traditional messaging systems, events are not deleted after consumption.
- key
- value
- timestamp
- metadata header
Example
Event key: “Alice”
Event value: “Made a payment of $200 to Bob”
Event timestamp: “Jun. 25, 2020 at 2:06 p.m.”
Producers
Producers are those client applications that publish (write) events to Kafka
Consumers
consumers are those that subscribe to (read and process) these events
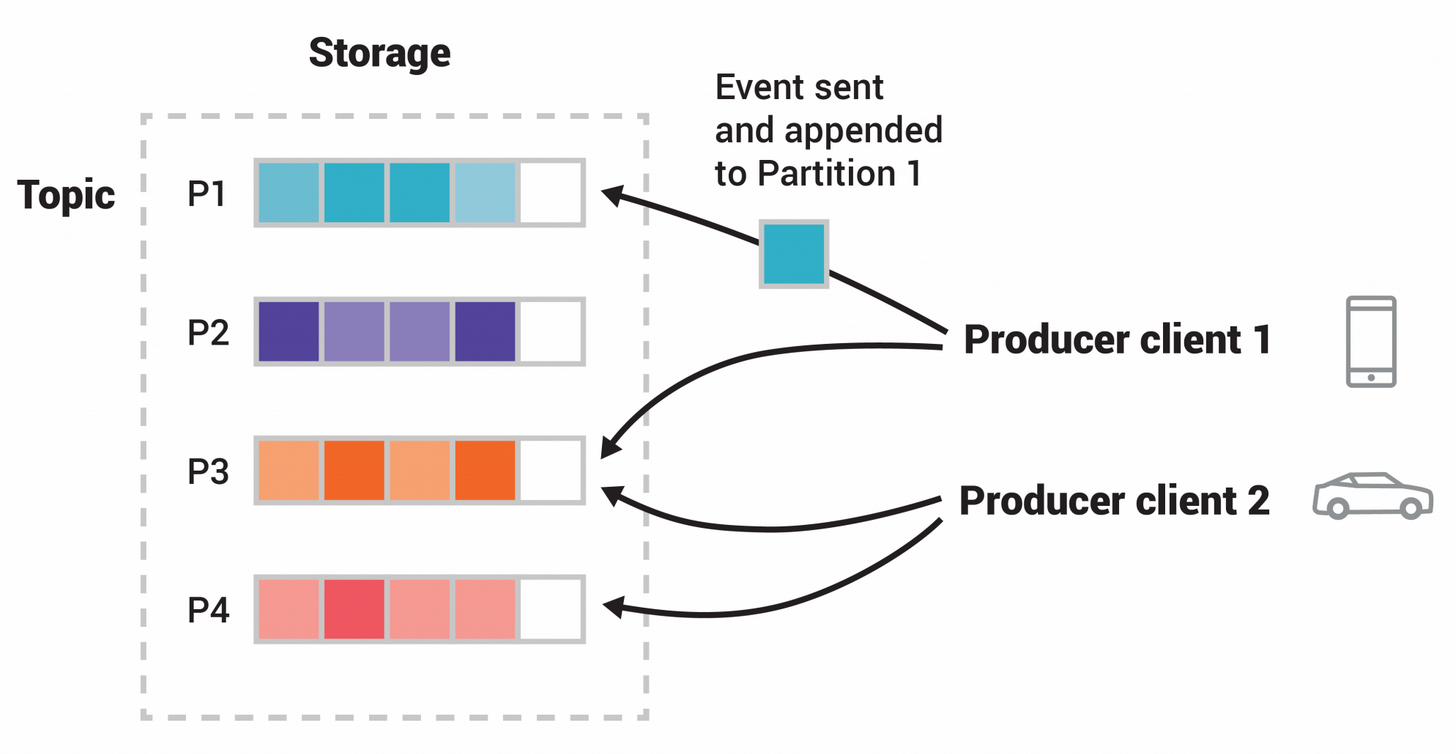
Topics
- Topics are partitioned, meaning a topic is spread over a number of “buckets” located on different Kafka brokers.
- Kafka guarantees that any consumer of a given topic-partition will always read that partition’s events in exactly the same order as they were written
- A common production setting is a replication factor of 3, i.e., there will always be three copies of your data. This replication is performed at the level of topic-partitions.
Kafka设计
All data is immediately written to a persistent log on the filesystem without necessarily flushing to disk. In effect this just means that it is transferred into the kernel’s pagecache.
Intuitively a persistent queue could be built on simple reads and appends to files as is commonly the case with logging solutions. This structure has the advantage that all operations are O(1) and reads do not block writes or each other.
Producer
LoadBalancing
- 生产者将数据直接发送给指定分区Broker集群的Leader
- Kafka的每一个节点都会维护一份元数据,保存哪些节点是活跃的以及不同topic不同分区的leader
- Producer Client可以指定数据发送到哪一个分区,机制可以是随机或者用户指定
Asynchronous Send
Batching is one of the big drivers of efficiency, and to enable batching the Kafka producer will attempt to accumulate data in memory and to send out larger batches in a single request. The batching can be configured to accumulate no more than a fixed number of messages and to wait no longer than some fixed latency bound (say 64k or 10 ms). This allows the accumulation of more bytes to send, and few larger I/O operations on the servers. This buffering is configurable and gives a mechanism to trade off a small amount of additional latency for better throughput.
Details on configuration and the api for the producer can be found elsewhere in the documentation.
Consumer
pull-based
Consumer Position
- Each Partition is Consumed by one consumer within the consumer group at any given time
- The Position is just an integer: offset
- This state can be check-pointed periodically
Offline Dataload
In the case of Hadoop we parallelize the data load by splitting the load over individual map tasks, one for each node/topic/partition combination, allowing full parallelism in the loading. Hadoop provides the task management, and tasks which fail can restart without danger of duplicate data—they simply restart from their original position.
Message Delivery Semantics
Producer
- Since 0.11.0.0, the Kafka producer also supports an idempotent delivery option which guarantees that resending will not result in duplicate entries in the log.
- the producer supports the ability to send messages to multiple topic partitions using transaction-like semantics: i.e. either all messages are successfully written or none of them are.
- If the producer specifies that it wants to wait on the message being committed this can take on the order of 10 ms.
- However the producer can also specify that it wants to perform the send completely asynchronously
- it wants to wait only until the leader (but not necessarily the followers) have the message
Consumer
考虑两种情况:
- Consumer消费完消息-Crash->保存offset(重复读取)
- Consumer保存offset-Crash->消费完消息(漏读)
Kafka的解决方案:
write offset & consume消息打包成一个事务,可设置不同的隔离级别
Replication
The unit of replication is the topic partition
We can now more precisely define that a message is considered committed when all in sync replicas for that partition have applied it to their log.
Only committed messages are ever given out to the consumer.
For Kafka node liveness has two conditions
A node must be able to maintain its session with ZooKeeper (via ZooKeeper’s heartbeat mechanism)
If it is a follower it must replicate the writes happening on the leader and not fall “too far” behind
Replicated Logs
Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write.
Our protocol for allowing a replica to rejoin the ISR ensures that before rejoining, it must fully re-sync again even if it lost unflushed data in its crash.
Log Compaction strategy ensures that Kafka will always retain at least the last known value for each message key within the log for a single topic partition.